У нас есть аудиодорожка. Нам нужно представить ее в виде вектора
Вообще говоря, аудиосигнал является аналоговым. Для записи в компьютер он дискретизируется:
$d\tau$ - время одного столбика, обратная к нему величина будет частотой дискретизации
Полученные высоты "столбиков" записываются в вектор, далее мы будем работать с ним
Существует множество различных способов дальнейшего анализа аудиосигнала - от простого выделения средней амплитуды (которая отвечает за громкость сигнала) и средней частоты (которая отвечает за высоту звука) до преобразования Фурье (сигнал все-таки частотный) или рассчета мел-кепстральных коэффициентов
Мы, однако, ограничимся простым векторным представлением звука (принцип которого изложен выше). Связано это будет частично с типом нейросети, которую мы будем рассматривать на примере простой задачи классификации звуковых дорожек.
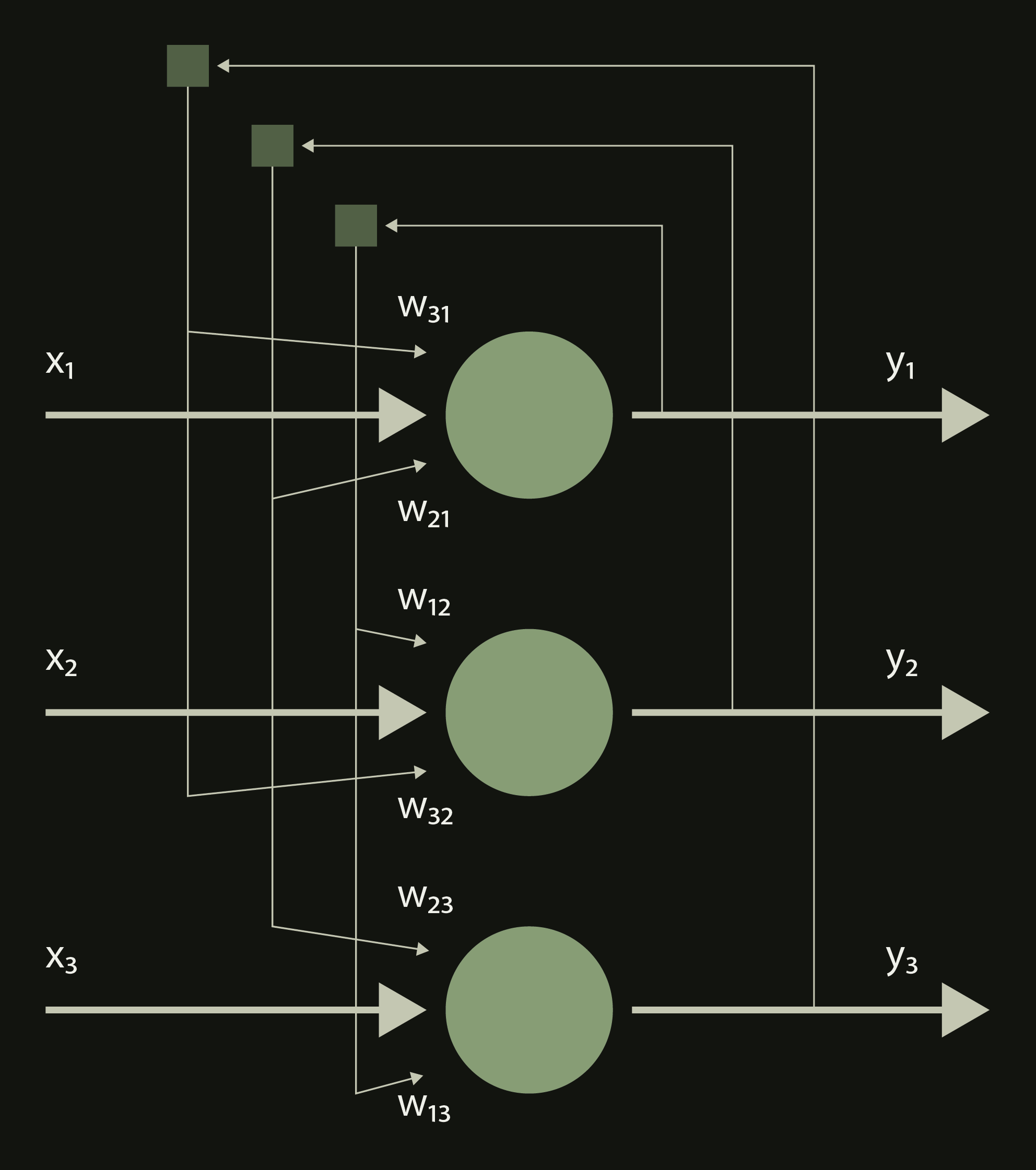
Сеть Хопфилда
Сеть, которую мы будем использовать для анализа - нейронная сеть Хопфилда
Как можем видеть, сеть состоит только из 1 слоя. Однако, сигналы образуют циклы. Каждый входной сигнал нейрона домножается на свой вес, активирует (или неактивирует или активирует частично, об этом чуть дальше) нейрон и идет дальше
В матричном виде сеть можно представить следующим образом:
$\mathrm{softmax}(z)_i = \frac{e^{z_i}}{\sum_{k} e^{z_k}}$ — функция активации.
Теперь обо всем по порядку
Softmax
Softmax - так называемая функция активации нейронов
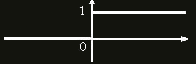
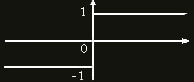
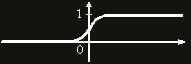
Роль функции активации - проанализировать входящий сигнал и вернуть 0, если нейрон точно не активировался и 1, если точно активировался. Существуют разные функции активации: линейные, дискретные, сигмоиды и прочие:
def SoftMax(signal):
s = np.exp(signal)
return s/sum(s)
Софтмакс - усовершенствованная сигмоида. Используем мы ее отчати потому, что она позволяет избежать ситуации, когда, например, активировалось сразу несколько выходных нейронов (а в условиях одного слоя сети это существенно). В нашем же случае мы можем увидеть, как сильно активировался нейрон
Матрица весов
Одно из главных достоинств нейросети Хопфилда - простота ее обучения.
Для любой нейронной сети необходимо определить матрицу ее весов. У нас это матрица $A$.
Сеть Хопфилда сводит входящий сигнал в один из эталонных сигналов. И для ее обучения эти эталонные сигналы (они же вектор-представления некоторого набора "идеальных" аудиодорожек) нужно расставить в матрицу весов по строчкам.
Иными словами:
Допустим, у нас есть 3 идеальных звука $x$, $y$, $z$
$$
x =
\begin{bmatrix}
x_1\\ x_2\\ \vdots \\ x_n
\end{bmatrix},\
y =
\begin{bmatrix}
y_1\\ y_2\\ \vdots \\ y_n
\end{bmatrix},\
z =
\begin{bmatrix}
z_1\\ z_2\\ \vdots \\ z_n
\end{bmatrix}
$$
Мы записываем их в матрицу $A$ в следующем виде:
$$
A =
\begin{bmatrix}
x_1&x_2&\cdots&x_n\\
y_1&y_2&\cdots&y_n\\
z_1&z_2&\cdots&z_n
\end{bmatrix}
$$
Тогда при перемножении некоторого нового аудиосигнала $v$ на полученную матрицу $A$ мы получим следующий результат:
$$
Av =
\begin{bmatrix}
x_1&x_2&\cdots&x_n\\
y_1&y_2&\cdots&y_n\\
z_1&z_2&\cdots&z_n
\end{bmatrix}
*
\begin{bmatrix}
v_1\\ v_2\\ \vdots \\ v_n
\end{bmatrix} =
\begin{bmatrix}
(v,x)\\ (v,y)\\ (v,z)
\end{bmatrix}
$$
Последующее применение softmax к полученному вектору "выделит", который из векторов $x$, $y$, $z$ в лучшей степени "приближает" наш вектор $v$, а дальнейшее умножение на матрицу $A^T$ даст в результате этот самый "наилучший вектор". Profit!
Сходимость
Итак, у нас есть почти все вводные. Давайте проанализируем полученную систему на сходимость. Напомним ее вид (чуть упрощенный):
$$\boxed{x' = A^T \mathrm{softmax}(Ax) - x}$$
На прошлом пункте мы увидели, что $A^T \mathrm{softmax}(Ax)$ вернет вектор, наилучшим образом приближающий $x$ (обозначим как $\mathrm{best}$)
Несложно понять, что система будет сходиться к $\mathrm{best}$
А значит решение полученного диффура является искомым решением задачи классификации
фактически, конечно, система работает несколько сложнее, так как $\mathrm{best}$ на самом деле является не константой, а функцией от $x$. Тогда с изменением $x$ "эталонный вектор", к которому идет система, тоже может меняться, однако же мы наверняка знаем, что эти эталонные вектора вещественны и определены, так что как минимум система не будет уходить в $\infty$, так что мы доказали ее устойчивость, но не асимптотическую.
Вы могли заметить при первом знакомстве с сетью Хапфилда заметить загадочный коэффициент $\beta$ в матричном уравнении, ее описывающем:
Влияет он, как несложно догадаться, на функцию $\mathrm{softmax}$
Как мы помним, при активации нейронов могут возникать ситуации, когда активируется сразу несколько нейронов. Коэффициент $\beta$ как раз регулирует подобные ситуации. Его увеличение усиливает разграничения между "эталонными векторами" внутри диффура, а уменьшение, напротив, размывает их
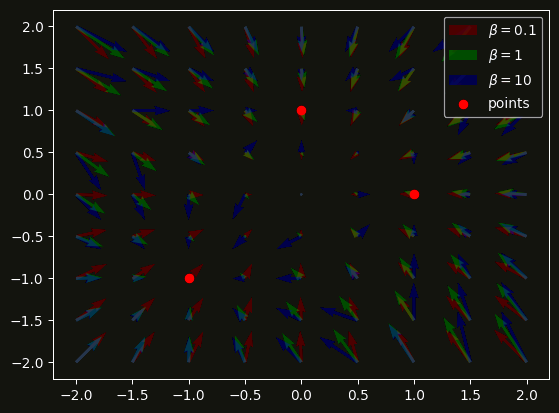
Легче всего это увидеть на векторных полях, соотвестсвующих диффурам при разных коэффициентах $\beta$:
Как можем видеть, при малых $\beta$ система сходится в нечто среднее между близкими "эталонными" векторами
Практическая задача
Осталось только написать код для решения практической задачи
Мы хотим по звуку угадать, его издает собачка или кошечка
1. Импортируем библиотеки
2. Создаем функцию, соответствующую правой части диффура
3. Пишем функции для численного метода решения диффура
4. Считываем эталонные вектора в матрицу $M$ (она же $A$)
Cat examples: 17
Dog examples: 21
5. Считываем новую аудиодорожку и решаем диффур
type in example name: dog 15
Sound:
Solution:
6. Определяем, кошечка или собачка
Полученный вектор - что-то очень близкое либо к чему-то из cats, либо к чему-то из dogs